Fan Out Experiment: How ChatGPT, Gemini, and Perplexity Recommend B2B Alternatives Across 270 Naturalistic Queries

Most of what gets said about AI search in B2B marketing is intuition that we’ve masked up as ‘analysis.’
The strategies typically follow the path of writing for ChatGPT, and optimizing for whatever new gimmick Google throws in the wild for us to hunt.
But almost no one has run the queries to capture what the AI does, and looked at the patterns.
So to do just that, I ran 270 queries across ChatGPT, Gemini, and Perplexity, asking each one for alternatives to three B2B SaaS products: Kustomer, Okta, and LinearB.
Thirty different phrasings of the same intent per product, across three LLMs. Polite, casual, frustrated, openly profane. Role-led, problem-led, comparison-led. I opted for this range to mimic what a real buyer covers during a real evaluation cycle.
How the experiment worked
I chose three products for what their categories represent.
- Kustomer sits in a mature customer support market with a settled competitive set.
- Okta operates in identity and access management, where one structural incumbent (Microsoft Entra ID) dominates.
- LinearB is in engineering analytics, a contested category with no clear winner yet.
The thirty phrasings per product were drawn from a ten-category taxonomy designed to test four dimensions of variation: formality, emotional valence, specificity, and directness.
- Direct-polite (“What are the best alternatives to Okta?”).
- Direct-casual (“Other tools like Okta?”).
- Frustrated-mild (“Okta isn’t working for us, what else is there?”).
- Role-led (“Best alternative to Okta for a small IT team”).
- Comparison-framed (“Tools like Okta but cheaper”).
- Reddit-style (“Anyone else hate Okta lol”).
Finding 1: The brand pool converges
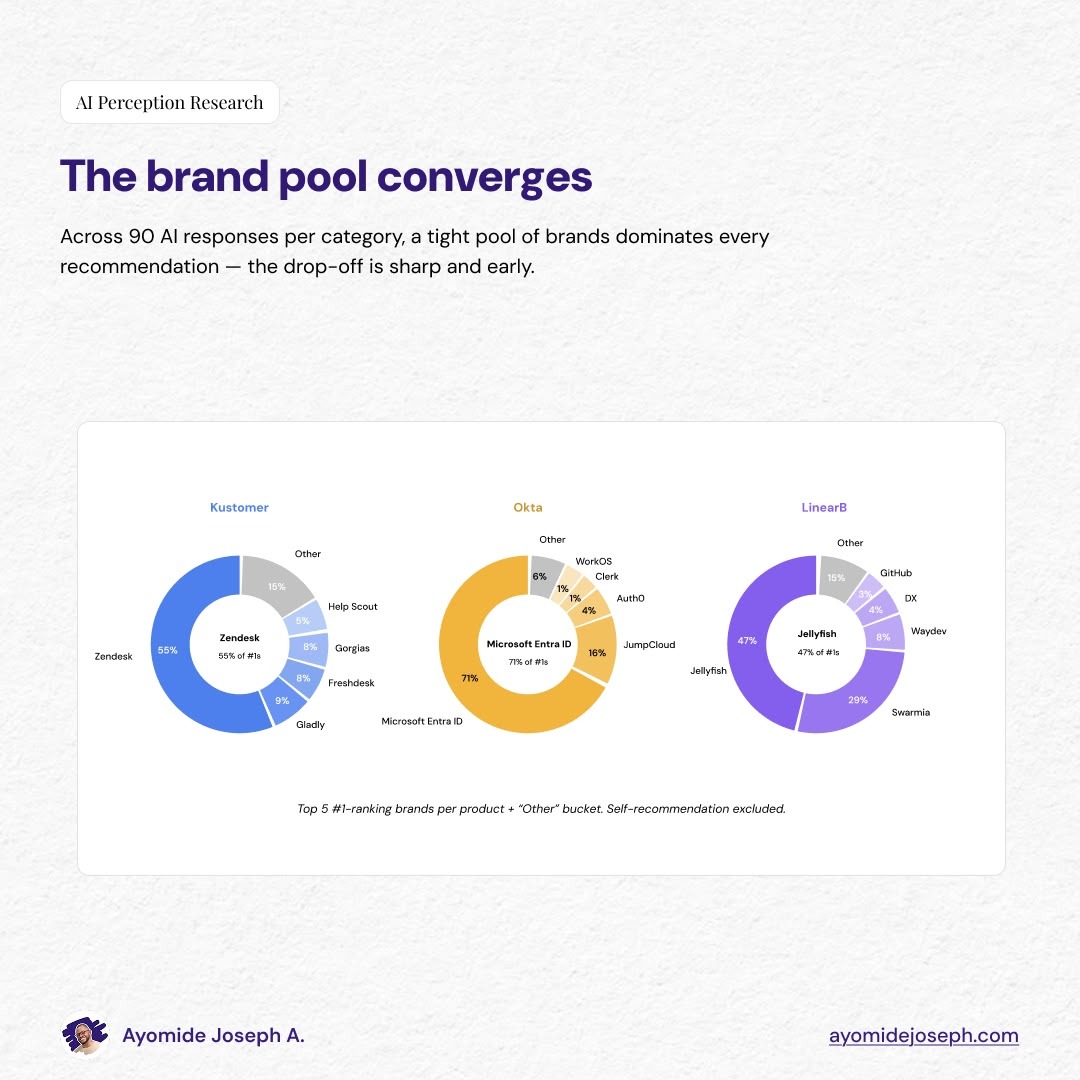
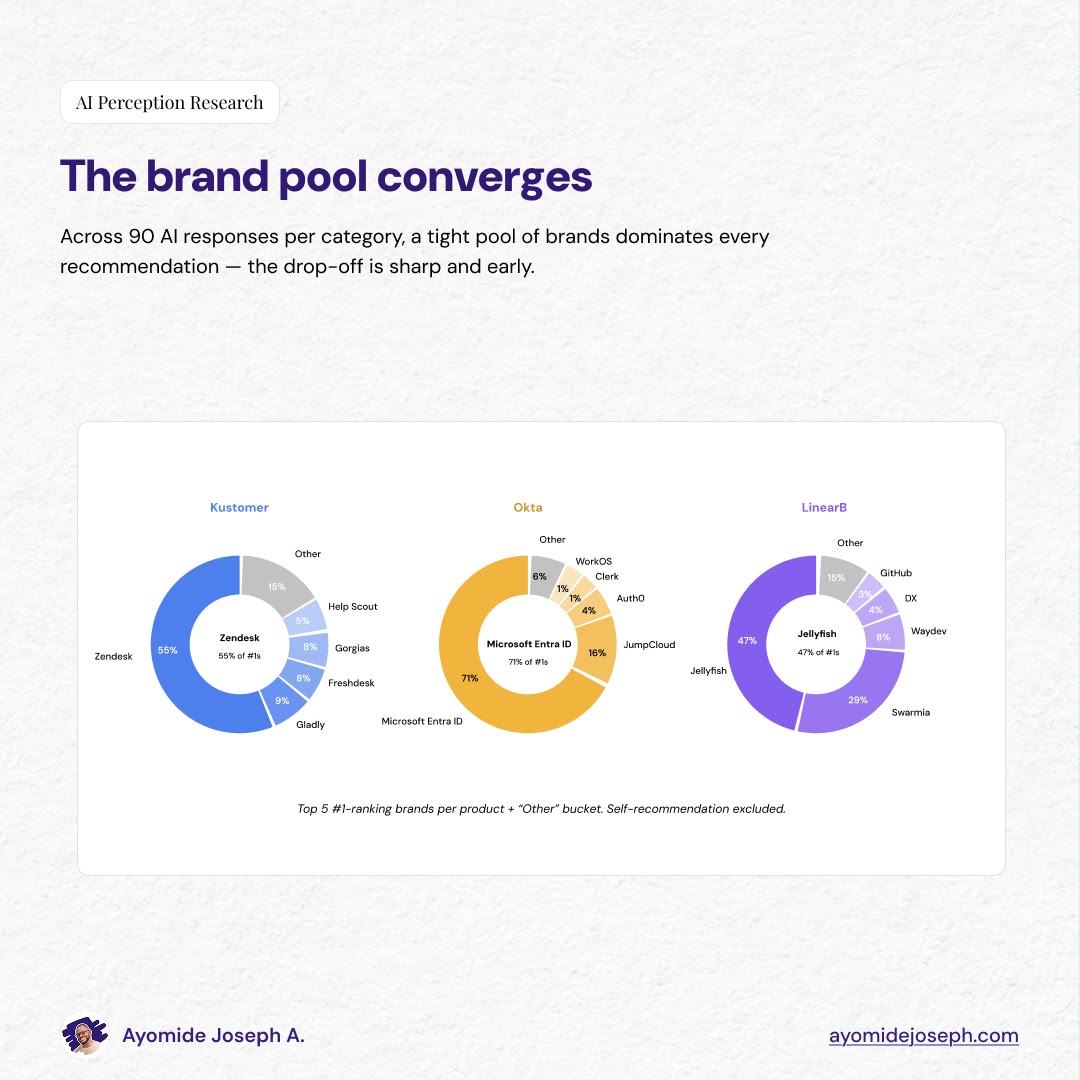
When buyers ask an AI search engine for alternatives to a B2B product, the recommendations come from a tight, repeating pool of brands.
Different phrasings produce different ranking orders, but they pull from the same set. As such, the phrasing matters less than the question itself.
The data is visible with Kustomer
In a comparison with Kustomer, across 90 responses, four brands appeared in the top five of almost every response: Zendesk 59 times, Gorgias 58, Freshdesk 57, Intercom 50.
The fifth-most-frequent brand was Gladly at 26—a sharp drop. By the time the list runs out of brands appearing more than 15 times across 90 captures, only seven companies have been named for the entire category.
Okta shows the same shape
Microsoft Entra ID appeared in the top five of 63 responses. JumpCloud 58. OneLogin 45. Ping Identity 43. Auth0 34. Five brands, almost every time.
LinearB is the same story
Swarmia 63, Jellyfish 62, Waydev 44, Haystack 32, DX 28.
The concentration sharpens at the #1 position. Microsoft Entra ID took the top spot in 71% of Okta queries where a #1 was named. Zendesk took 55% of Kustomer #1 spots. LinearB is more contested as Jellyfish took 47%, and Swarmia 29%, but the pattern still holds.
The brands inside the consensus pool also overlap heavily across LLMs.
For Okta, all three LLMs picked Microsoft Entra ID as their #1 most often. For Kustomer, all three picked Zendesk. Three different models, built on different training data, retrieving differently, arrived at the same answer.
The implication of this splits things into two aspects: AI search has an awareness layer, and brands either live inside it or they do not.
Brands inside the consensus pool show up across most phrasings, across most LLMs, across most query types. Brands outside the pool show up rarely, deep in responses, or only when the buyer's phrasing is unusually specific. No phrasing trick lifts a brand from outside the pool into the consensus position. The AI is drawing from training data and retrieved sources that already reflect a settled view of the category.
Finding 2: Specificity breaks convergence. Emotion does not.
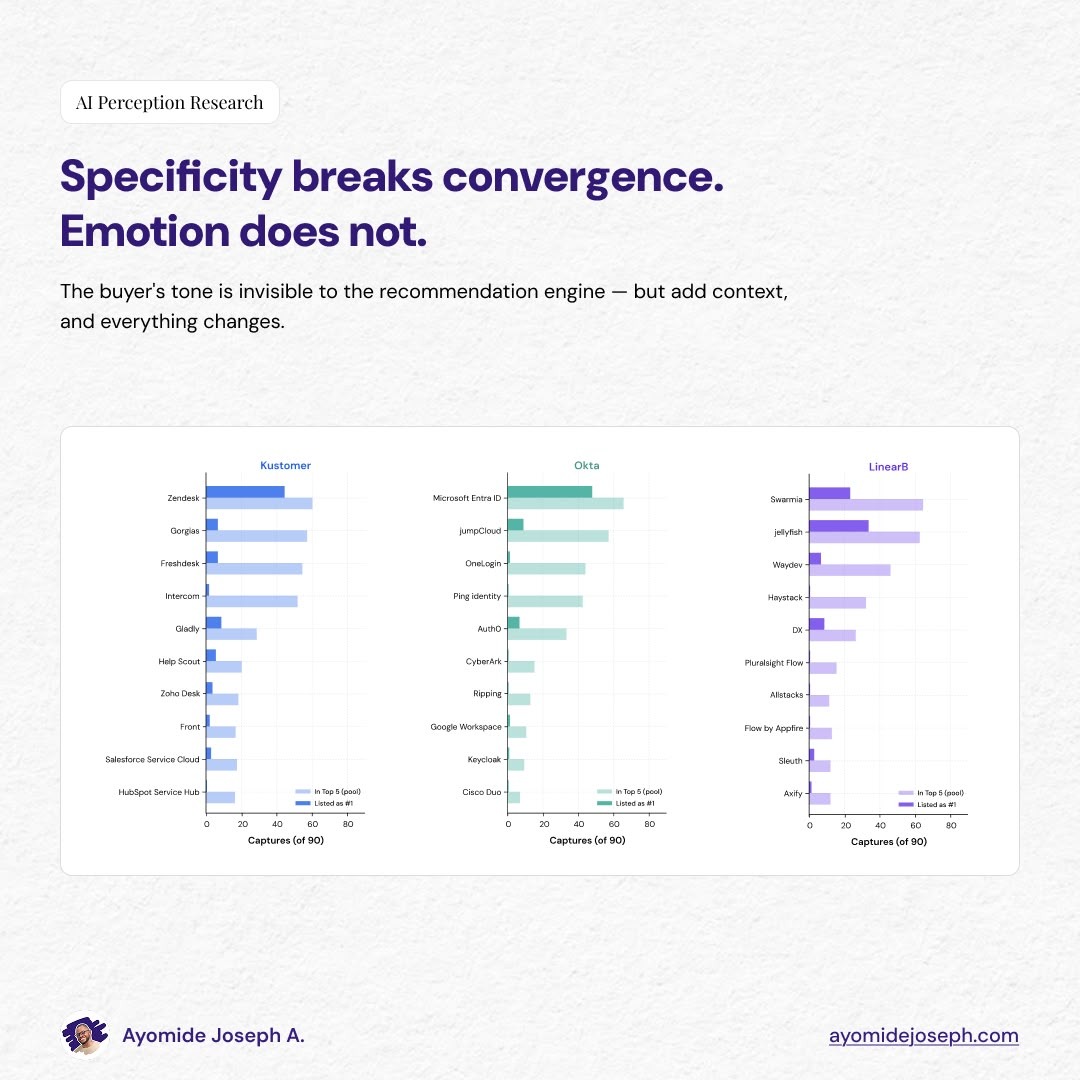
I came into the experiment expecting emotional phrasings like frustrated, profane, and Reddit-voiced to surface different brands than calm professional phrasings.
The conventional thinking says the AI matches the buyer’s emotional register and pulls forward different recommendations. But the data argues the opposite.
Okta is a good example of this. Across Direct-casual, Frustrated-mild, and Frustrated-profane phrasings—nine queries in each category—Microsoft Entra ID came back as the #1 recommendation 100% of the time. Polite, mildly annoyed, openly profane also had the same answer.
Kustomer also behaved the same way. Zendesk took the top spot in 78% of Direct-polite phrasings, 78% of Frustrated-mild, and 78% of Frustrated-profane. The buyer’s tone is invisible to the recommendation engine.
Although there is one exception in the emotional band. Reddit-style phrasings (“Anyone else hate Kustomer lol”) produced almost no brand recommendations at all.
Across the Okta and LinearB Reddit-style queries, zero brands were recommended in any of the 18 responses. The LLMs read the question as venting rather than purchase intent and responded in kind. ChatGPT and Gemini for example validated the frustration, and explained what users complain about, without ever recommending alternatives.
There’s also a contrast that appears the moment specificity enters the query. Phrasings that anchor to a use case, a role, or a comparison frame fragment the recommendation immediately.
Comparison-framed phrasings: “Tools like Kustomer but cheaper,” “Like Okta but with better UX” — produced seven different #1 brands across Kustomer, six across Okta, and seven across LinearB. The pool of competitors is the same as it was for the polite phrasings. The ranking inside the pool fractures.
Role-led phrasings show the same effect with different reshuffling. For Kustomer, the question “Best alternative to Kustomer for a small CX team” surfaced Help Scout as the top recommendation. The same question framed for enterprise compliance surfaced Salesforce Service Cloud.
Zendesk, the category leader at 55% of #1 spots overall, slipped to second or third in both. The buyer’s context—e.g., small team, enterprise scale, specific compliance posture— pulled different brands forward from the same underlying pool.
The strategic implication of this also splits two ways:
- Content strategies that match the emotional register of the buyer optimize for an intent that AI search has already collapsed. The recommendation surfaces the same brand whether the buyer is calm or furious. The work has cultural value and brand-affinity value, but it carries no recommendation-level leverage.
- Content strategies that match the contextual specificity of the buyer optimize for an intent that AI search has not yet decided. As such, the recommendation fragments. There is still room to be the brand that surfaces when the buyer says “for a small IT team,” even when a different brand surfaces for the broader phrasing.
Finding 3: The three LLMs are not interchangeable
A lot of B2B marketing strategies treat “AI search” as a single optimization target. It postulates the idea that if you get good at it, the work pays off across ChatGPT, Gemini, Perplexity, and whatever comes next.
While it’s not a bad idea, the data argues this framing is wrong.
The three LLMs studied behave like three different products, and the differences are big enough that a team optimizing for one will leave visibility on the table with the others.
Retrieval behavior
The first and largest gap is in how often each LLM actually searches the web before answering.
- Perplexity searches on every single query (90 of 90 captures).
- Gemini searches on 74% of queries. ChatGPT searches on 44% of queries.
- The remaining 56% of ChatGPT responses came from training data alone, with no retrieval step at all.
A ChatGPT answer drawn from training data is the model summarizing what it learned during training. That training data was scraped from the open web months or years before the user typed the question.
The brands ChatGPT will recommend from training data are the brands that had visibility during its training window. New entrants, recent rebrands, and emerging competitors are systematically underweighted in training-data responses.
The pattern of when ChatGPT decides to search the web is what sharpens the finding. Direct-polite queries fired web search 100% of the time.
- Frustrated-mild fired search 89% of the time.
- Problem-led queries triggered search only 33% of the time.
- Outcome-led 22%.
- Comparison-framed 22%. Role-led 11%.
- Reddit-style queries did not trigger a single web search across nine attempts.
- For ChatGPT visibility on direct alternative-seeking queries, fresh web content matters because ChatGPT will retrieve and cite it.
- For ChatGPT visibility on contextual queries (the kind buyers actually use during real evaluation) the only path in is being part of the training data ChatGPT already has.
That makes long-term brand mentions across the web, persistent presence in established publications, and accumulated SEO signal far more important for ChatGPT than for the other two LLMs.
Gemini and Perplexity behave differently because they search more reliably. Gemini still has a 26% training-data fallback, with a milder version of the same intent-shape effect. Perplexity has no fallback to manage.
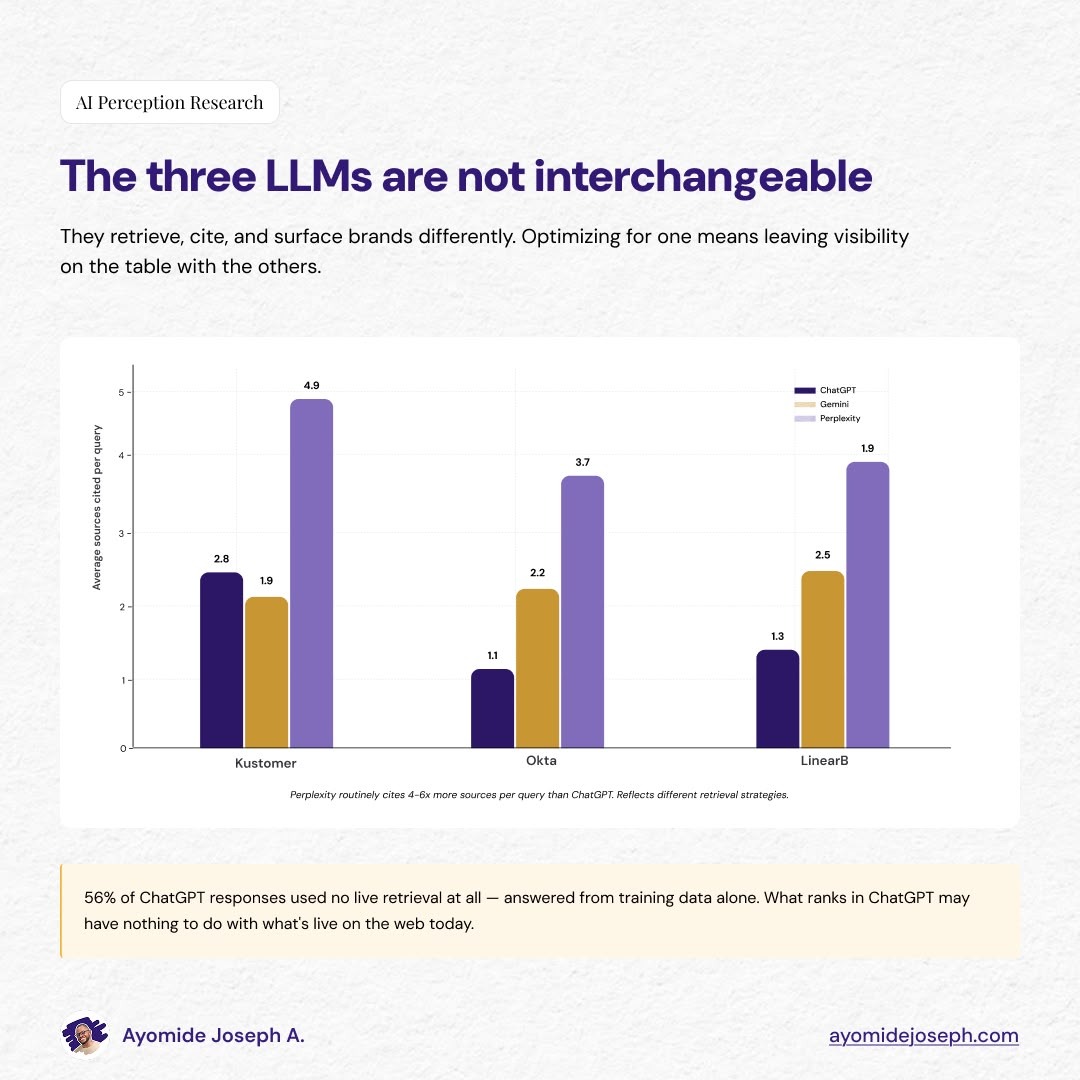
Citation density
The second gap is in how many sources each LLM cites per response. ChatGPT averaged 1.7 sources per query, Gemini 2.2, and Perplexity 4.2. The gap also widens within specific products. For Kustomer, ChatGPT cited 2.8 sources per query, Gemini 1.9, and Perplexity 4.9.
For B2B teams, the conversation here moves to leverage.
A single mention on a high-authority source—e.g., a Gartner peer review, or a citation in a frequently-pulled listicle—has outsized influence on what ChatGPT recommends, because ChatGPT cites so few sources per query that each one carries more weight.
On Perplexity, the same single mention is diluted across three or four other citations.
Brand pool breadth
The third gap is more interesting because it goes against the intuitive read. The instinct is to assume the LLM with the most retrieval and the most citations would also surface the widest universe of brands. Again, the data does not support that.
For Kustomer, Perplexity surfaced the widest brand pool with 25 unique brands in the Top 5 alone, 32 when “Other brands mentioned” are counted. ChatGPT was tighter at 18/24. Gemini tighter still at 17/18.
For Okta and LinearB, the order flips. ChatGPT surfaced 35 unique brands for Okta when including the long tail, and 38 for LinearB—more than either of the others. Perplexity was the narrowest of the three for both products.
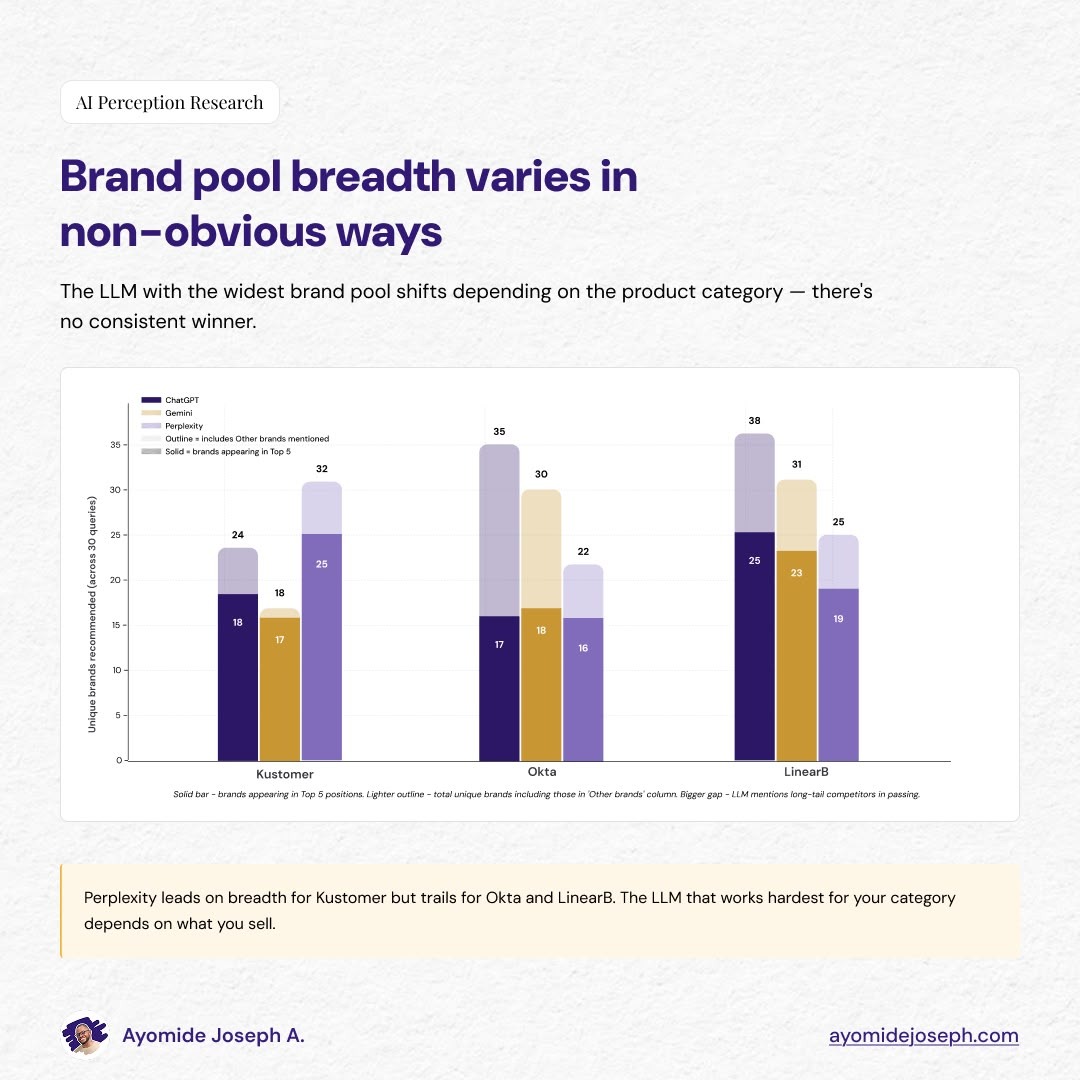
The three LLMs require three optimization profiles.
- For ChatGPT, the priorities are training-data presence and high-authority citations.
- For Gemini, vendor-blog discoverability and review-aggregator presence.
- For Perplexity, citation breadth across diverse source types.
A team that builds for only one of these will see uneven results across the others.
Finding 4: Source mix reveals LLM identity
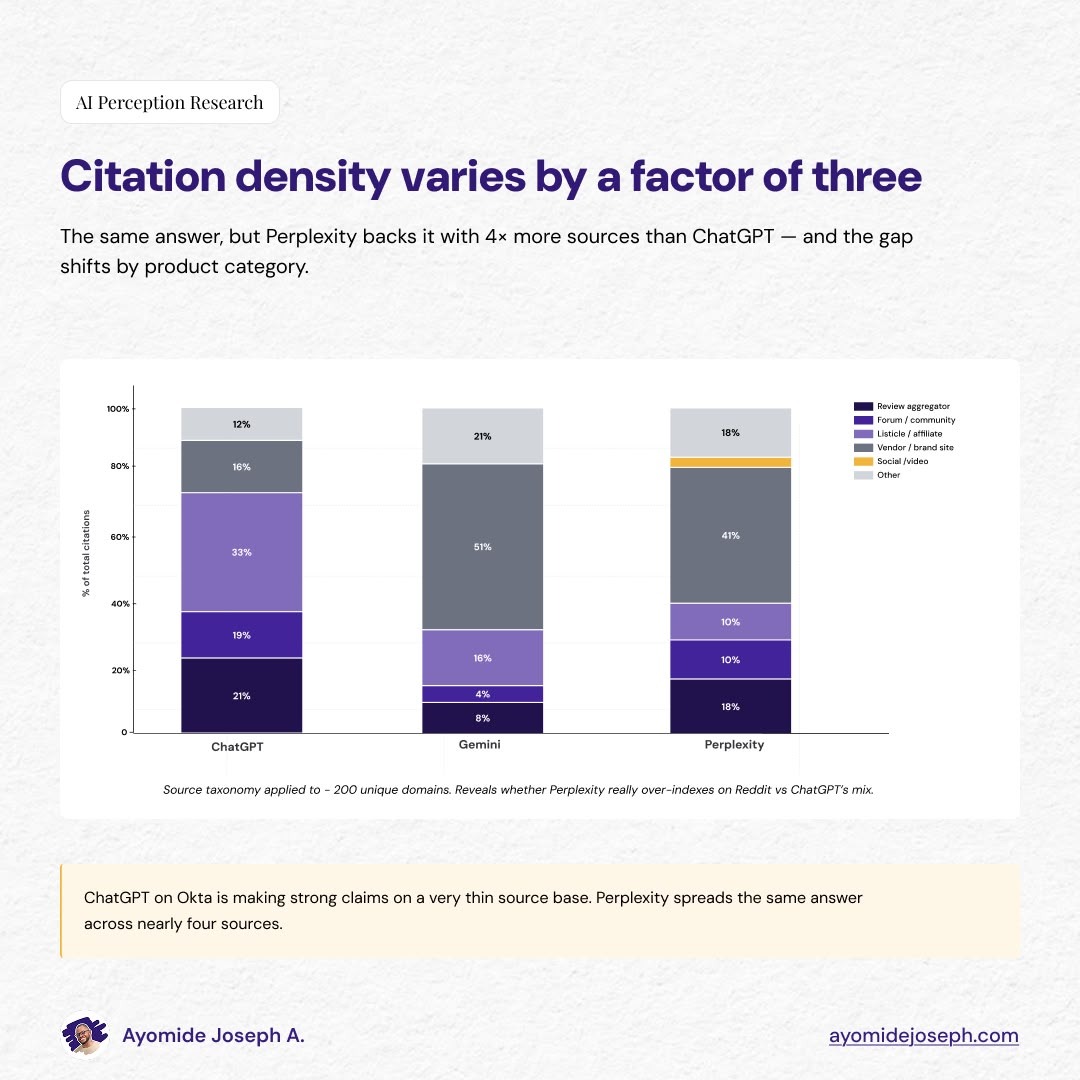
A recommendation engine is the sum of the sources it pulls from. Two LLMs can converge on the same brand for the same query, but if the sources backing that recommendation are different, the strategic implications are different too.
The three LLMs draw from materially different source mixes, and the differences hold across every product in the study.
Across all 270 captures, the LLMs collectively cited 730 sources. G2 and Reddit were the two most-cited domains (81 and 70 citations respectively). After those two, the long tail diverges sharply by LLM.
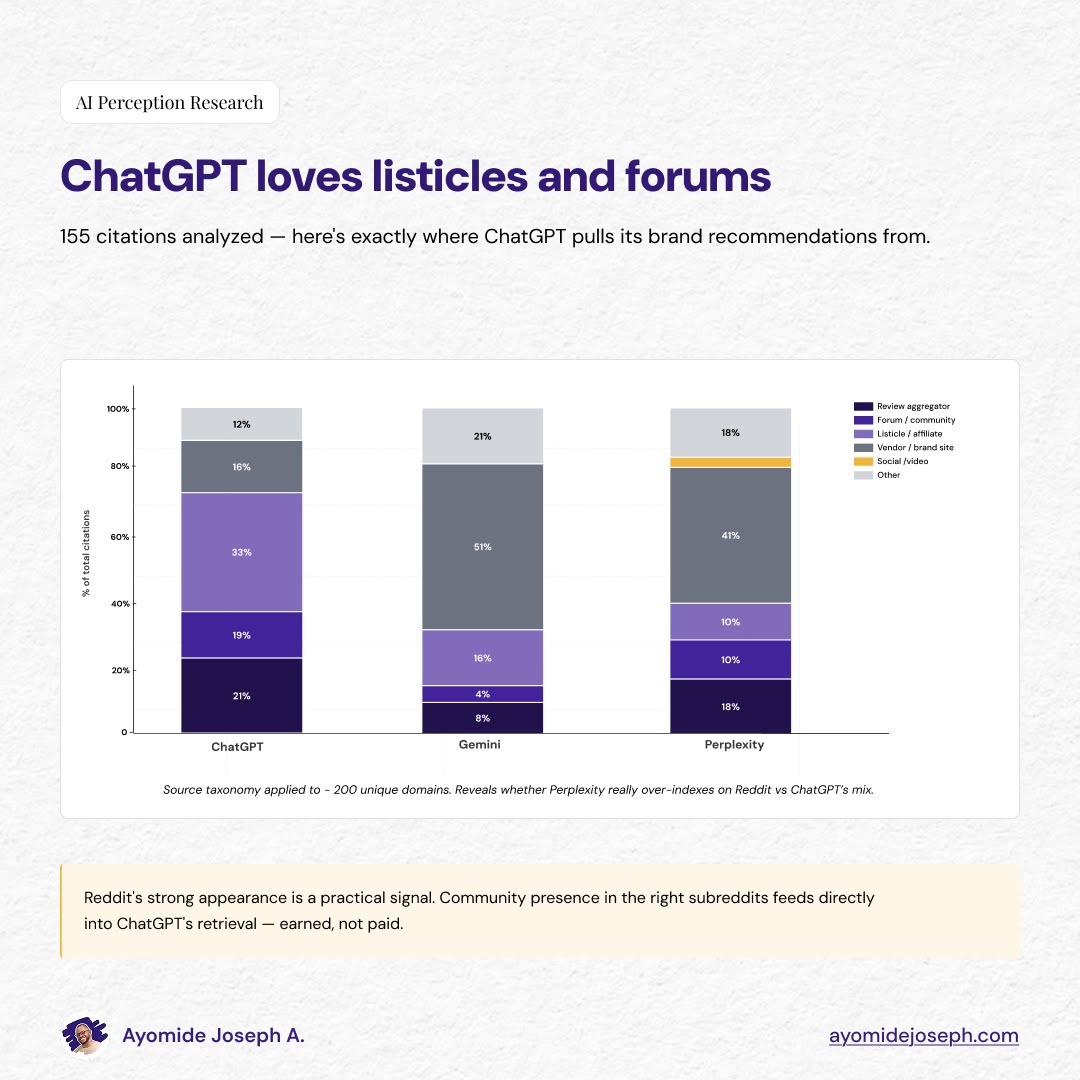
ChatGPT is a listicle and forum engine
Of ChatGPT’s 155 citations, 33% came from listicle and affiliate content. 21% from review aggregators. 19% from forums (almost all Reddit). 16% from vendor sites.
The top ChatGPT-specific citations after G2 and Reddit were sites like Ringly, RankRed, and Pandev which are listicle-format affiliate publications.
Gartner appeared, but with only 7 citations across all 90 queries. The Tier 1 analyst presence was thin.
For B2B teams optimizing for ChatGPT visibility, placement in the top-ranking listicles in the category is the most direct path to citation. Listicle publishers accept inclusion requests, sponsored placements, and earned coverage.
Gemini is a vendor blog engine
Of Gemini’s 199 citations, 51% came from vendor and brand sites. Review aggregators were 8%. Forums 4%. Listicles 16%. Half of everything Gemini cites is sitting on a vendor’s own owned domain.
What a competitor’s blog says about its category, its differentiators, and its comparison ecosystem becomes the basis for what Gemini will tell a buyer about every competitor in the category, including yours. The competitive blog has become a direct participant in Gemini’s recommendation logic.
A team writing strong “X vs Y” content on its own domain is feeding the model that will get asked about both X and Y. A team that has not invested in this layer is letting competitors write the model’s training signal.
Perplexity is the breadth engine
Perplexity cited 376 sources across 90 queries, more than ChatGPT and Gemini combined. Its mix was the most balanced of the three: 41% vendor sites, 18% review aggregators, 10% forums, 10% listicles, 4% social and video.
Perplexity cited G2 51 times across the dataset, more than twice ChatGPT’s 24 and three times Gemini’s 16. It cited Reddit 33 times. It was the only LLM in the study that consistently cited YouTube. Its source mix is closer to a search engine results page than to a curated authority shortlist.
Strategically, Perplexity rewards visibility breadth. Because it cites four times more sources per query than ChatGPT, no single source carries the same weight.
The uncomfortable read across all three LLMs is that for Gemini and Perplexity, one of the most influential source categories is the competitor’s own content. For most B2B SaaS teams, competitors are influencing the AI’s view of your brand far more than the team has accounted for.
The only way to win is to participate at the same level. In this case, creating own-domain editorial depth, competitive comparison content, and category-defining writing on the topics buyers will eventually ask the AI about.
Finding 5: Category structure shapes how locked-in AI search becomes
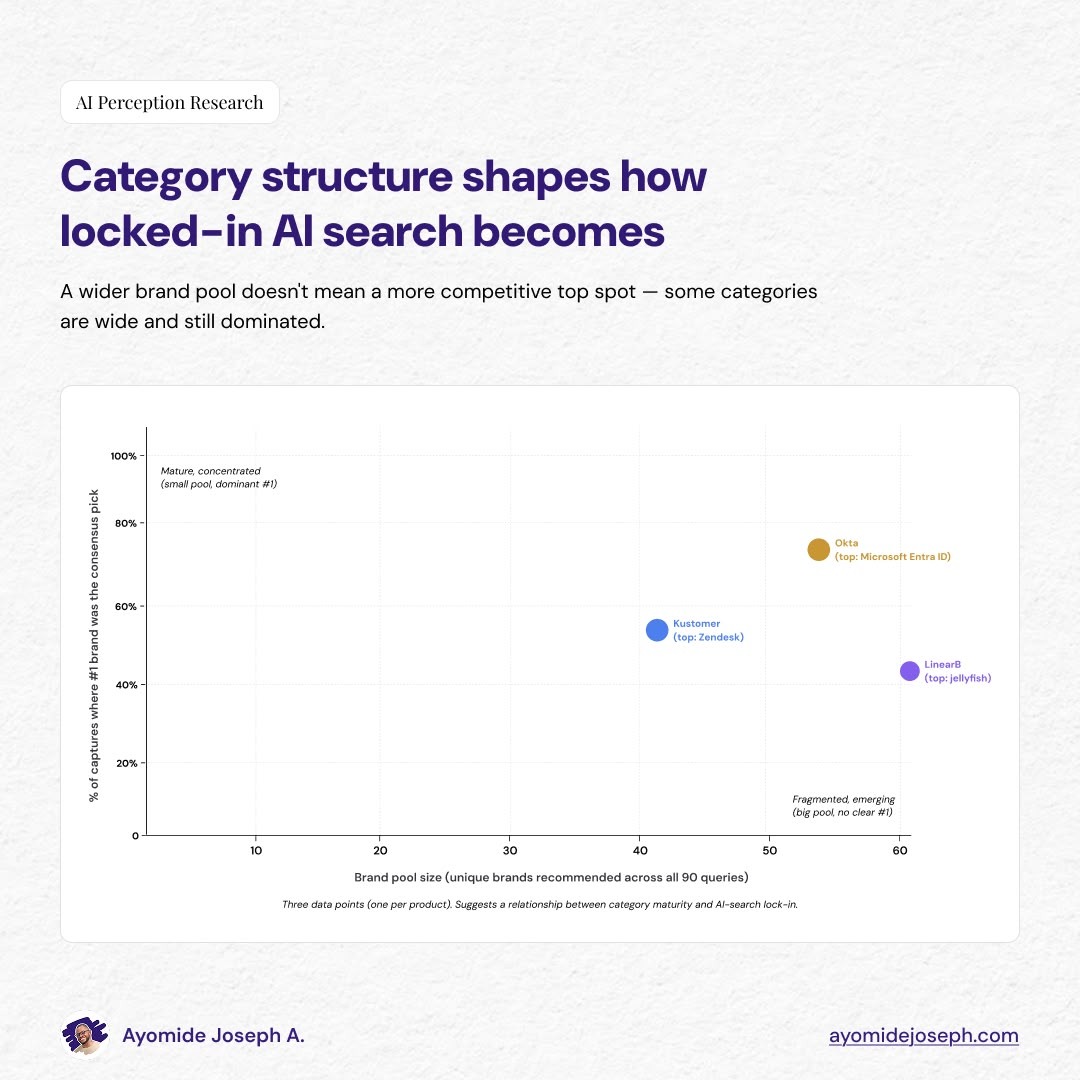
The first four findings apply broadly. The pool converges, specificity breaks ranking, LLMs behave differently, source mix matters. These patterns held across all three products.
The fifth finding is about what differed.
The three verticals produced three distinct lock-in profiles:
- Kustomer: 43-brand pool, Zendesk holds 55% of #1 spots
- Okta: 55-brand pool, Microsoft Entra ID holds 71% of #1 spots
- LinearB: 61-brand pool, Jellyfish holds 47% of #1 spots
The thought process that a bigger pool means more fragmentation is wrong.
Okta has the second-largest pool and the highest concentration. LinearB has the largest pool and the lowest concentration. Kustomer sits in between on both axes. Pool size alone fails to explain lock-in but category structure does.
Okta
Okta sits in a category with a structurally dominant incumbent. Microsoft Entra ID is the default IAM solution for the largest segment of buyers — i.e., enterprise organizations already running Microsoft 365 or Azure. That dominance is reflected in every signal the LLMs draw on.
As such, any time a buyer asks about Okta alternatives, all three LLMs converge on the same answer with high confidence. There is room in the consensus pool for JumpCloud, Auth0, Ping Identity, and others, but there is no room at the top.
Kustomer
Kustomer sits in a category with a clear leader and no incumbent of Microsoft Entra ID’s structural weight. Zendesk takes #1 55% of the time. The remaining 45% spreads across thirteen different brands.
The customer support category has been mature long enough that multiple credible vendors have accumulated their own visibility signals. Buyers get Zendesk most of the time, but specific framings like “for ecommerce,” “for SMBs,” “for enterprise” pull different brands forward. The category is led but not locked.
LinearB
LinearB sits in a category that has not yet decided who wins. Jellyfish takes #1 47% of the time, Swarmia takes 29%, and the choice between them depends heavily on which LLM the buyer asks. ChatGPT favors Swarmia. Perplexity favors Jellyfish. Gemini splits roughly evenly.
Beyond the top two, six more brands held the #1 spot at least once.
The framework matters because there is no universal playbook for winning AI search. There are three playbooks. Where a brand sits in its category determines which one applies, and the work required to move position is different in each.
What this means if you work in B2B SaaS
Five findings, taken together, argue for a shift in how B2B SaaS teams think about content and category positioning.
AI search has an awareness layer that brands either live inside or do not. The first question for any B2B team is whether the brand is in the consensus pool for its category. Everything else is downstream of that question.
- Within the pool, the recommendation is moved by contextual content. The teams that build deep use-case, role-led, and comparison-framed content for the segments where the AI has not yet converged will earn ranking visibility that emotional content cannot reach.
- The three LLMs are not interchangeable.
- ChatGPT requires training-data presence and high-authority citations.
- Gemini requires owned-domain depth and competitive comparison content.
- Perplexity requires breadth across the citation ecosystem.
A single “AI SEO” budget that treats them as one channel will produce uneven results.
Get the full report
The full report includes the complete methodology, the phrasing matrix for all three products, the source-mix analysis broken down by LLM, the category-structure framework, and a chapter on the strategic implications for B2B SaaS teams.
If the patterns above match what you are seeing in your own work, or if they contradict it sharply enough to be useful, the full report gives you the underlying data and the framework to act on it.